
In today’s interconnected digital landscape, the risk of cyber attacks looms large, with malware posing as a pervasive and continuously evolving threat. As organizations intensify their efforts to strengthen cyber defenses, the integration of machine learning and cybersecurity emerges as a powerful strategy. In this technical blog, we delve into the detailed process of harnessing machine learning for precise malware classification, emphasizing feature extraction, data cleaning, exploratory data analysis (EDA), and feature selection.
Enhancing Features for Machine Learning
Feature engineering involves leveraging domain expertise to understand and refine features, often with input from analysts or domain specialists. The objective is to craft features that effectively distinguish between different prediction classes, sometimes necessitating modifications to original features to optimize their utility in ML/AI models.
In the context of feature engineering, the process typically begins with a comprehensive analysis of PE files and their internal attributes. Through this investigation, it becomes evident that key attributes of PE files are contained within components such as the DOS header, file header, section header, and optional header. Furthermore, features related to file sections are categorized based on their nature.
The next phase involves feature extraction and data preprocessing, essential steps in refining the dataset for models. This process entails basic checks on features, such as identifying section names within the dataset. Unique section names in files are extracted and analyzed to differentiate conventional section naming patterns in clean files.
Refining Data for Analysis
Before starting into analysis and EDA, ensuring the authenticity of our datasets is paramount. We thoroughly check for empty and missing values in our data and also ensure that all features have the correct data type, preparing it for EDA and model training.
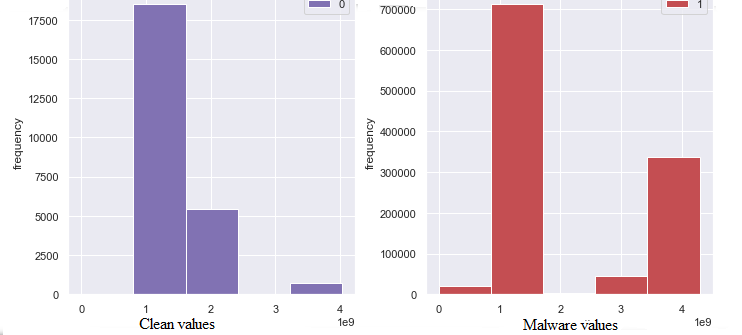
Histogram Plot: A histogram plot provides a visual representation of the frequency distribution of a feature. Ideally, histograms exhibit a bell-shaped curve resembling a Gaussian distribution, which helps in understanding the central tendency and spread of the data. A histogram plot needs to be studied for each feature of both clean and malware data. If a distribution difference is noticed for a feature between clean and malware data, but they fall within the same value range, then this kind of feature should be considered for model training. If there’s no notable difference in distribution between clean and malware data for a feature, it preferred to exclude the feature.
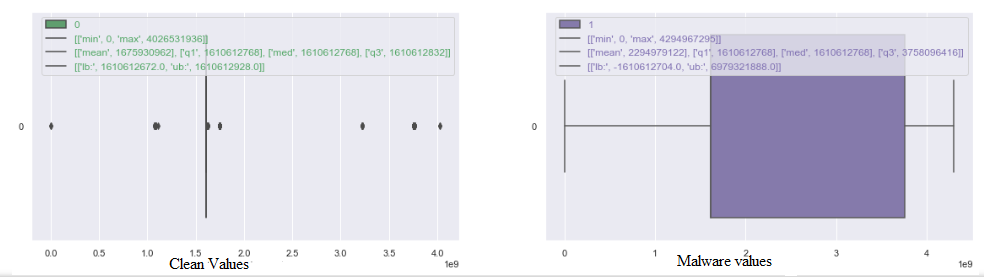
Box plot: Box plots provide valuable insights into how data is spread out, whether it’s skewed, and whether there are any outliers. They show the range of values, with lines extending to the minimum and maximum values within a certain range from 1.5 times of interquartile range (IQR).While examining these plots patterns need to be identified, if a feature has outliers in the clean data but those same values fall within the box region for malware data, it suggests that the feature can help distinguish between clean and malware files.
Violin plot: Violin plots are like a combination of histograms and box plots, offering a deeper dive into the distributional properties of data and providing a comprehensive view. After examining features with histograms and box plots, violin plots add clear validation to each selected feature. They give us a deeper understanding of how data is spread out and any patterns or fine details that may exist.
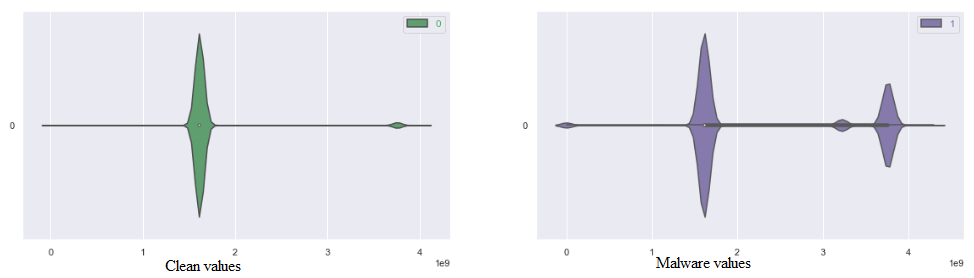
By using the above plot for analysis, a huge number of features can be reduced so that only reliable features are considered, which shows the distinction between clean and malware.
Managing Datasets for Effective Model Training
This step is crucial as it allows for exploring various permutations and combinations within a dataset. It includes essential tasks such as balancing the dataset, where different ratios of clean data to malware data can be tested based on the model’s performance and expected metrics. Adjusting these parameters can significantly impact the model’s training and overall effectiveness in detecting malware.
Managing Feature Variability: To enhance feature consistency, various standardization and normalization techniques are employed. These methods ensure that features are scaled to specific value ranges, streamlining the model training process for faster convergence and improved efficiency in achieving desired model outcomes.
Various normalization techniques can be utilized to preprocess data effectively:
- StandardScaler: It transforms the data such that it has a mean of 0 and a standard deviation of 1. StandardScaler is typically employed when the distribution of the feature values is assumed to be Gaussian (normal distribution).
- MinMaxScaler: It linearly transforms each feature such that the minimum value of the feature becomes 0, and the maximum value becomes 1. MinMaxScaler is particularly useful when the distribution of the data does not follow a Gaussian distribution.
- Normalize: This technique scales each feature individually to have a unit norm, meaning the sum of the squares of the elements of each feature vector is 1. Normalize is useful when the pattern of the data matters more than its magnitude, also it performs row normalization.
- Averaging: This method scales all values of a sample to fall within the range of 0 to 1 by dividing each value by the sum of all values in the sample.
- Log Normalization: In this approach, all values of a sample are transformed to be within the 0 to desired range that can be the maximum value in the dataset by taking the logarithmic value of each sample. One challenge with this technique is handling the presence of zero values within the sample. To address this issue, zeros are replaced with a very small value before applying the logarithmic transformation.
Model Training
It is essential to execute all the necessary preprocessing steps outlined in the preceding sections to ensure that the dataset is ready for direct use in training, testing and validation.
For training machine learning models, various algorithms can be employed, including:
- Decision Tree
- Random Forest
- Logistic Regression
- XGBoost
- LightGBM
- Extra Tree Classifier
Each algorithm is designed with specific mathematical formulations tailored to different feature characteristics and use cases.
Additionally, depending on the dataset’s requirements, specific features, and domain-specific information, AI models such as
- CNN
- VGG19
- ResNet50
- InceptionV3
- EfficientNet
can also be integrated. These models are optimized for handling complex data and extracting meaningful features for classification tasks.
The performance metrics need to be decided as per the expected results of the ML model, in the case of malware detection false positive rate(FPR), recall and precision are the primary metrics.
Conclusion:
In the ongoing fight against cyber threats, the combination of machine learning and other cyber security majors stands out as a promising solution. By carefully extracting features, cleaning data, and conducting thorough exploratory data analysis (EDA), we equip ourselves to reduce the false positive numbers(accuracy in detecting the clean files) and also by maintaining the recall(accuracy in detecting the malware files) in a suitable range.